
写爬虫经常会遇到需要登录的情况,有的网站可能会做一些前端加密之内的操作,去慢慢分析包可能还不如借助无头浏览器模拟人工登录来的效率,当然如果还有人机验证的话这篇文章就不在考虑范围内了
首先介绍下需要用到的工具browserless, 通过docker运行的chrome无头浏览器, 下面是docker compose的配置文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
networks: bridge: driver: bridge services: Chrome: image: browserless/chrome:latest restart: always ports: - 3000:3000 networks: - bridge environment: TIMEOUT: 600000 CONNECTION_TIMEOUT: 600000 |
安装好过后, 通过ip:3000可以进入到一个debug页面,在这里可以用来调试后面所需要运行的代码
下面放个示例,用于登录themoviedb并获取cookie
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
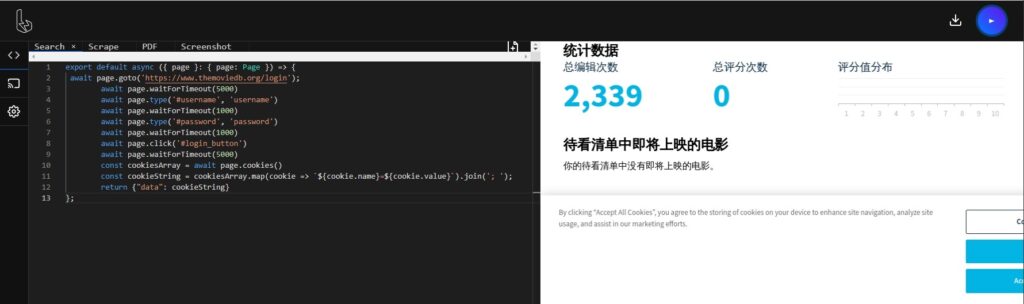
export default async ({ page }: { page: Page }) => { await page.goto('https://www.themoviedb.org/login') await page.waitForTimeout(5000) await page.type('#username', 'username') await page.waitForTimeout(1000) await page.type('#password', 'password') await page.waitForTimeout(1000) await page.click('#login_button') await page.waitForTimeout(5000) const cookiesArray = await page.cookies() const cookieString = cookiesArray.map(cookie => `${cookie.name}=${cookie.value}`).join('; ') return {"data": cookieString} }; |
如下图所示,编辑好代码过后点击右上方运行,等待完成过后浏览器就会下载下来一个包含cookie文本信息的文件。
下面是在python下使用的示例, 其中要注意示例中的payload开头,和在网页中调试的代码会有一些区别
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import requests def get_cookie(): url = "http://192.168.7.24:3030/function" payload = """module.exports = async ({ page }) => { await page.goto('https://www.themoviedb.org/login') await page.waitForTimeout(5000) await page.type('#username', 'username') await page.waitForTimeout(1000) await page.type('#password', 'password') await page.waitForTimeout(1000) await page.click('#login_button') await page.waitForTimeout(5000) const cookiesArray = await page.cookies() const cookieString = cookiesArray.map(cookie => `${cookie.name}=${cookie.value}`).join('; ') return {"data": cookieString} };""" headers = { 'User-Agent': 'Apifox/1.0.0 (https://apifox.com)', 'Content-Type': 'application/javascript' } response = requests.request("POST", url, headers=headers, data=payload) return response.text if __name__ == '__main__': t = get_cookie() print(t) |